


Table of Contents
Text-to-speech has become a cornerstone of voice AI, powering everything from scheduling assistants to customer support agents and multilingual automation. Aura-2 delivers the natural and realistic speech users expect, but it is also engineered for the rigorous demands of business use cases. Beyond human-like intonation, it prioritizes clarity, precision, and responsiveness. These qualities are essential for real-time voice agents where accuracy and speed are just as critical as voice quality.
Today, we are excited to announce that Aura-2 now supports five additional languages:
🇳🇱 Dutch 🇫🇷 French 🇩🇪 German 🇮🇹 Italian 🇯🇵 Japanese
These join our existing English and Spanish models to provide a robust infrastructure for global voice applications.
This expansion helps developers deliver consistent, multilingual voice experiences via our API without sacrificing naturalness, pronunciation accuracy, or low-latency performance.
Why These Languages Matter for TTS
Each new Aura-2 language inherits unique phonological and prosodic challenges that make high-quality TTS difficult. However, getting these details right is critical for business applications where clarity prevents costly errors.
Here is why these languages are impactful additions:
Dutch Sample (nl)
🇳🇱 Dutch: Vowel richness and compound-heavy words Dutch has long vowels, diphthongs, and ultra-long compound nouns. Natural TTS must handle stress placement and smooth glides between complex vowel forms while keeping numeric data clear.
French Sample (fr)
🇫🇷 French: Liaison, elision, and continuous flow French uses fluid connected speech (liaisons) and dropped sounds (elisions). This requires a TTS engine to master subtle transitions without sounding choppy, especially when reading strings of numbers like contact information.
German Sample (de)
🇩🇪 German: Precision with long compounds and consonant clusters
German’s long words, clustered consonants, and consistent stress rules demand a voice model that enunciates clearly without sounding robotic. This is vital for complex scheduling and time-based data.
Italian Sample (it)
🇮🇹 Italian: Open vowels and musical intonation Italian TTS must preserve melody and vowel openness without exaggeration. Aura-2 maintains the natural rhythm of Italian speech even when delivering transactional updates involving currency.
Japanese Sample (ja)
🇯🇵 Japanese: Politeness markers, pitch accent, and mixed scripts Japanese blends kanji, kana, and loanwords while relying heavily on pitch accent. Aura-2 ensures smooth phrasing and consistent tone. This is also a strong example of structured-speech correctness, where the model must seamlessly switch between Japanese script and alphanumeric codes.
Human Preference Results for Conversational Voice
In addition to audio samples and system-level performance metrics, we evaluate Aura-2 using blind human preference testing focused specifically on conversational voice quality.
In these evaluations, human annotators compared voices from three vendors at a time and selected the voice that sounded most natural for conversational use cases such as customer service, interviews, and casual dialog. Each evaluation produced a single winner, resulting in a random baseline win rate of 33.3%.
The charts below highlight conversational performance by language, reflecting how well Aura-2 aligns with real-world expectations for interactive voice applications.
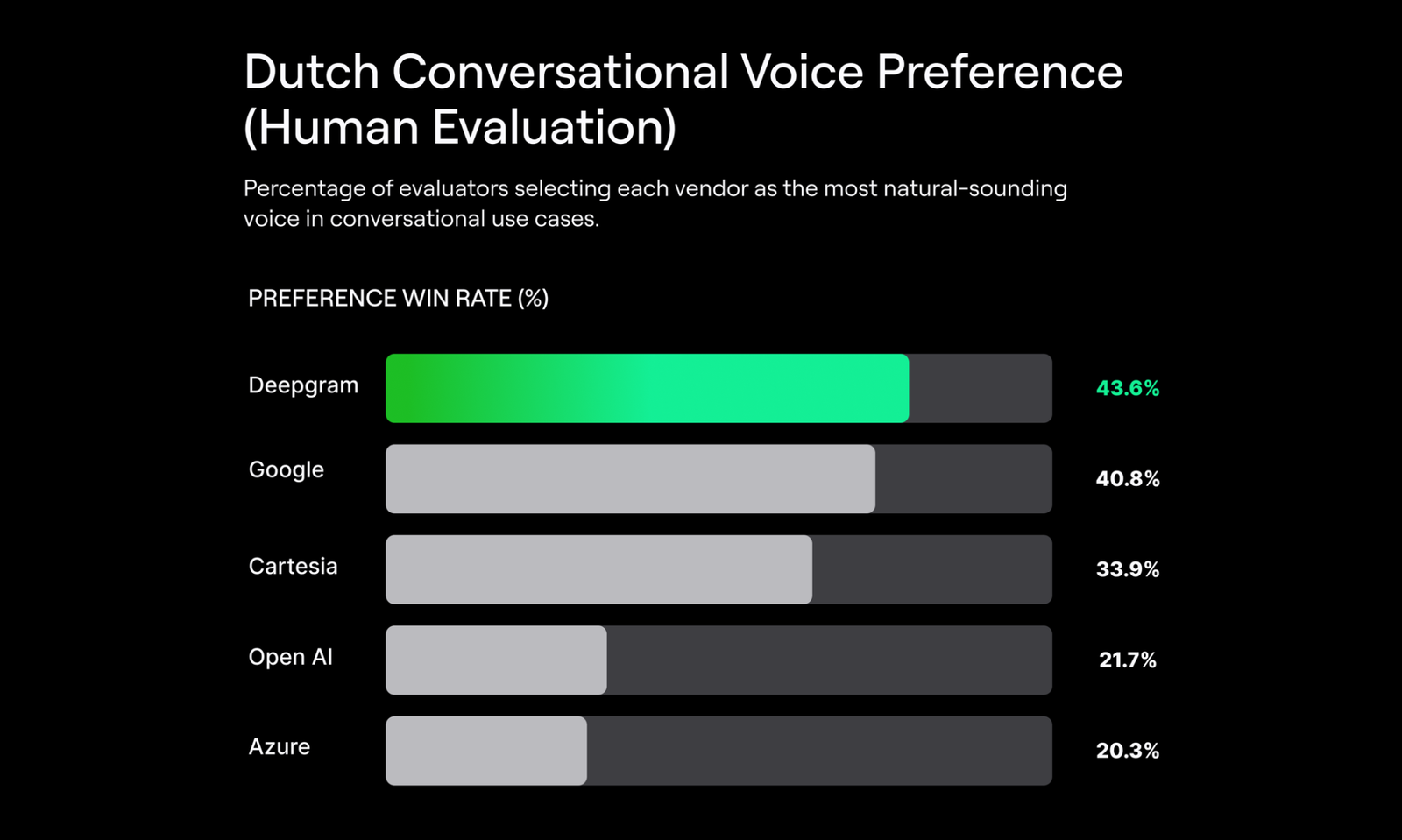
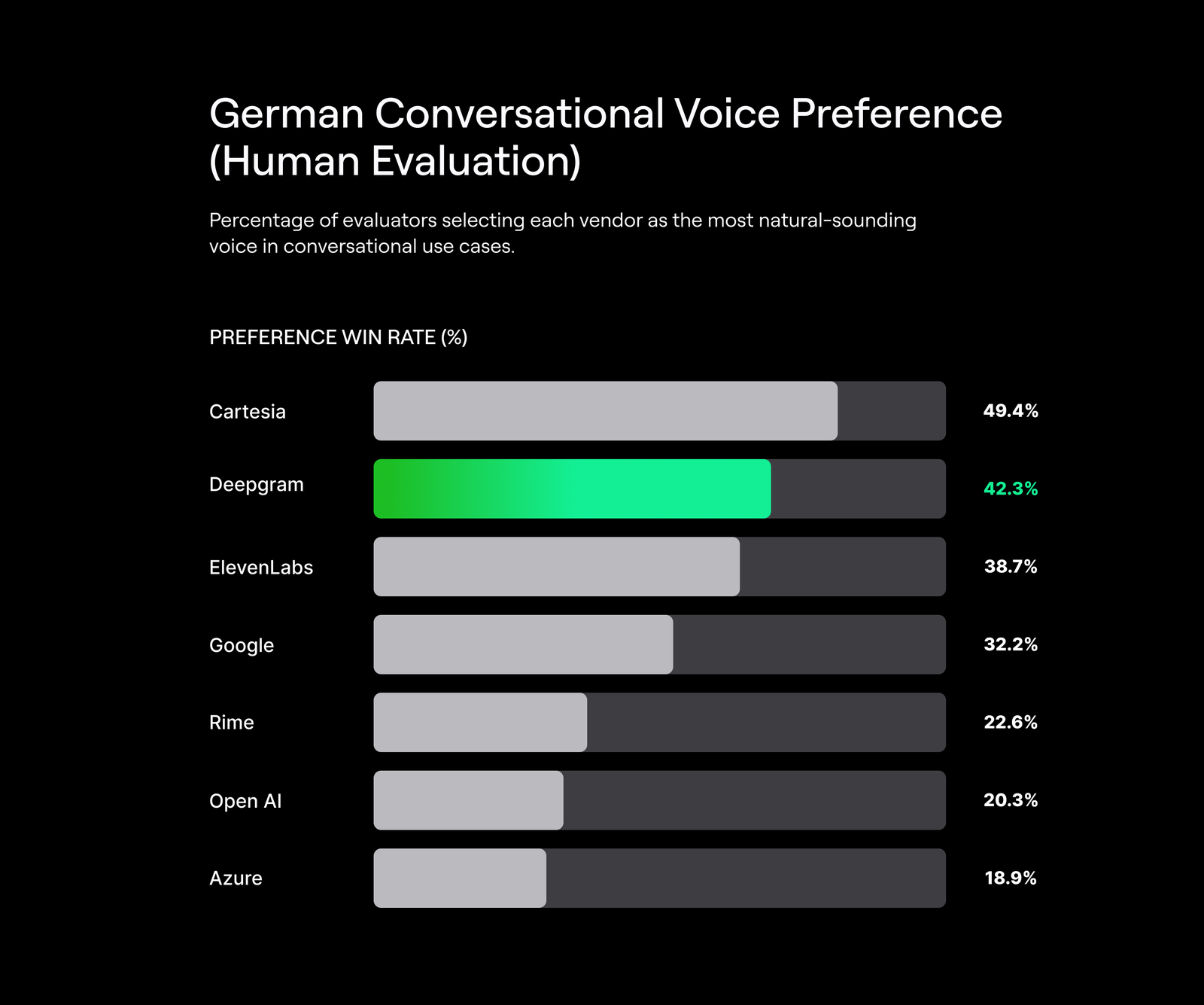
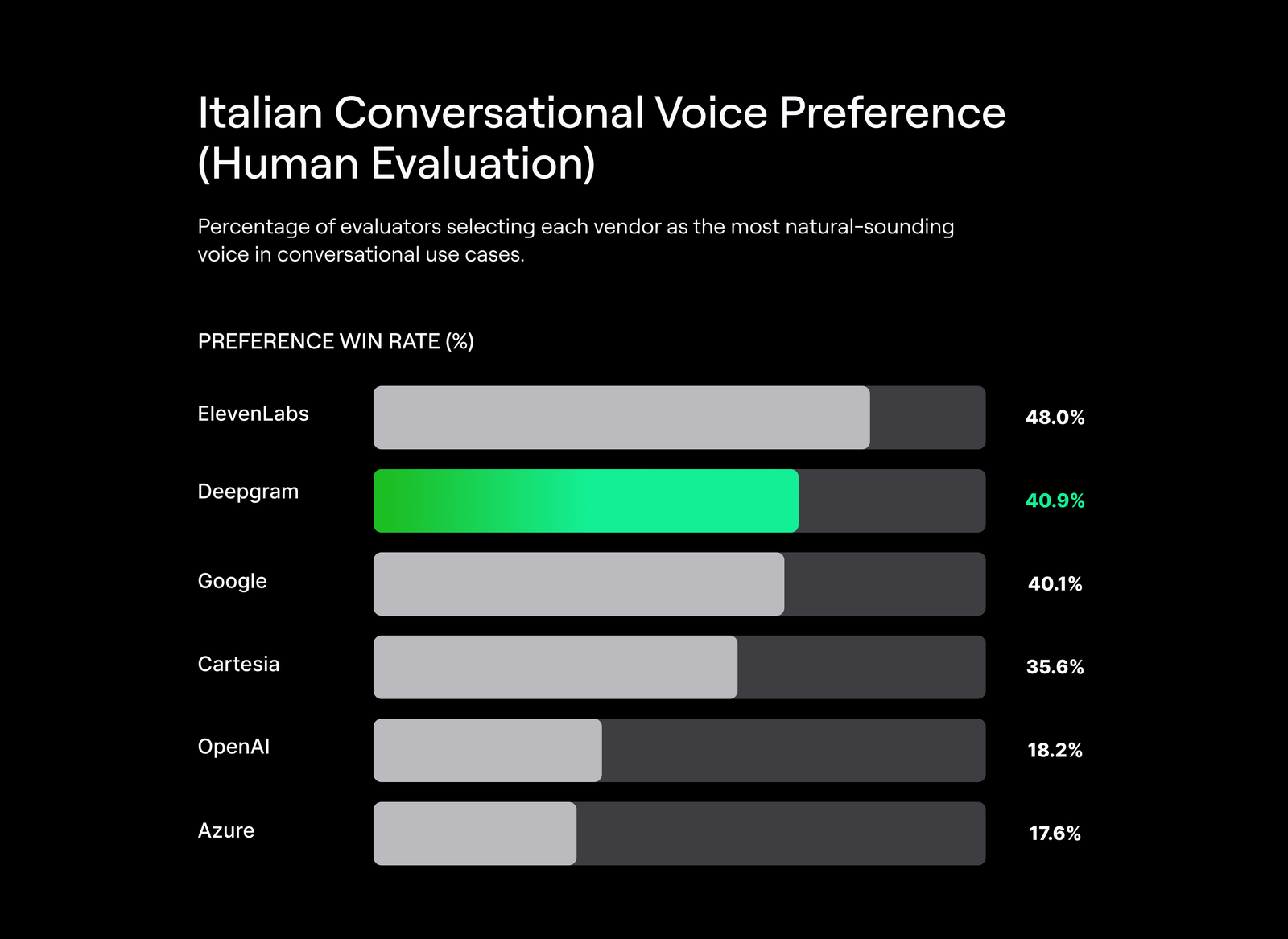
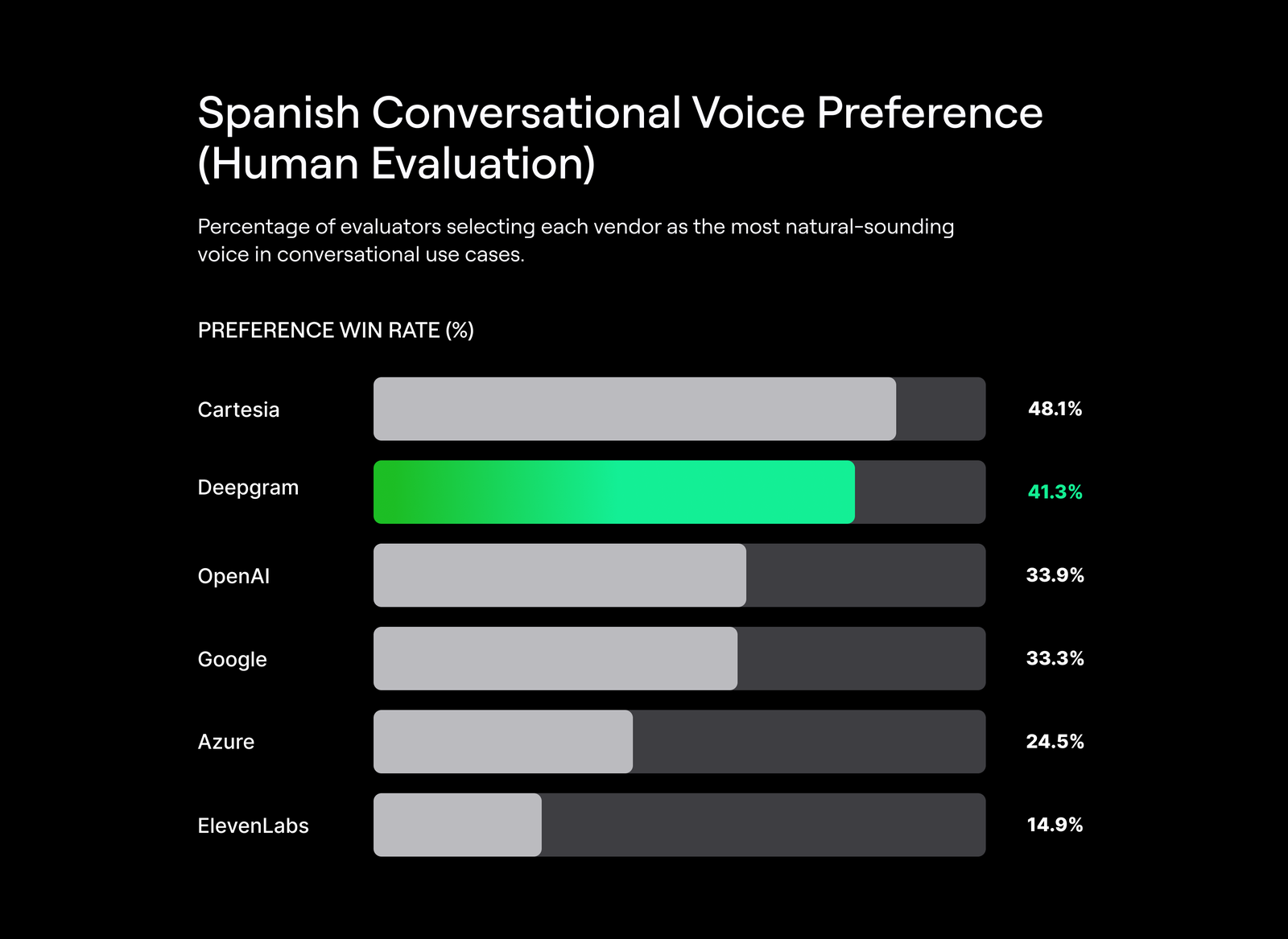
About these evaluations: Results are based on blind human preference testing for conversational voice prompts. Each evaluation compares three vendors and produces a single preferred voice (random baseline: 33.3%). Charts show conversational win rates by language.
What the results show
Across the languages highlighted here, Aura-2 demonstrates strong conversational preference in scenarios that prioritize clarity, pacing, and consistency over exaggerated expressiveness.
- Dutch: Aura-2 ranks first in conversational preference, with the highest win rate among evaluated vendors.
- German, Italian, Spanish, and Japanese: Aura-2 consistently ranks among the top conversational voices, indicating strong alignment with customer-service and interactive speech expectations across multiple language families.
These results reflect Aura-2’s design focus on business-ready conversational speech, where voices must sound natural, reliable, and intelligible over extended interactions.
Unified Infrastructure for Global Scale
Aura-2 continues to evolve as a unified voice synthesis infrastructure for global products and workflows. Instead of applying a single prosodic pattern to every language, Aura-2 adapts to each language’s unique phonology, whether it involves pitch accents, liaisons, or compound stress rules.
For developers and enterprise teams, this means:
- Consistent performance across diverse global markets via a single API.
- High-precision pronunciation for structured data like IDs, currency, and times.
- Sub-200ms latency that ensures fluid, real-time conversational flow.
- High reliability under streaming loads with stable performance even during high-volume concurrency.
- Simplified infrastructure that eliminates the need to stitch together different vendors for different languages.
Getting Started
Switching to any of the newly supported languages is simple. Update your API request with the appropriate language code.
Bash
curl https://api.deepgram.com/v1/speak \
-H "Authorization: Token YOUR_DEEPGRAM_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "aura-2",
"language": "fr",
"text": "Bonjour, comment puis-je vous aider ?"
}'New language codes:
nl, fr, de, it, jaFor a complete list of available voices and to hear audio samples for each region, refer to the TTS Voices and Languages documentation. You can also visit the Deepgram Playground to input your own text and test performance in real-time.
Looking Ahead
With five new languages now live, Aura-2 continues its progress toward full global coverage. Accuracy, adaptability, and real-time reliability continue to improve across language families and acoustic environments.
The goal is clear: voice AI that works everywhere, for everyone. We are building text-to-speech that sounds natural, responds instantly, and works globally, regardless of the complexity of the business use case.
Unlock Enterprise-Grade Voice AI Today
Sign up free and unlock $200 in credits, enough to generate over 13 million characters of synthesis. Explore details on our TTS Voices and Languages page and hear Aura-2’s natural, high-precision performance for yourself.








